많은 언어에서 [] 키워드는 배열을 의미한다. 왜 기본적으로 연속된 데이터 타입을 사용할까?
링크드 리스트가 아닌 배열을 사용하는 이유를 정리해본다.
링크드 리스트(Linked List)
링크드 리스트의 구조는 서로 다른 노드의 연결구조다. 각 노드는 다른 주소를 가지고 있고, 다음 노드의 주소를 알고 있기 때문에 연결이 가능하다.
이미지로 표현하면 아래와 같다.
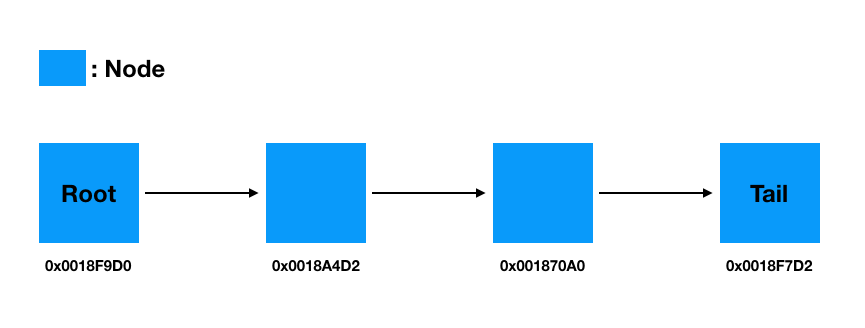 <Linked List>
<Linked List>
코드로 표현하면 아래처럼 표현할 수 있겠다. 예제는 메모리 개념을 코드로 표현하기(포인터) 위해 고 언어로 작성됐다.
1 | |
더블 링크드 리스트(Double Linked List)는 위 구조에서 이전 노드도 알 수 있도록 프로퍼티를 추가하면 된다.
1 | |
위 코드에서 볼 수 있듯이 마지막 위치(tail)을 알고 있는 링크드 리스트는 데이터를 Append 할 때 성능은 O(1)의 속도를 보여준다. (링크드 리스트의 메커니즘은 자료구조를 정리할 때 다뤄봐야겠다)
또 이전 노드를 알 수 있는 더블 링크드 리스트는 Remove 할 때도 O(1)의 성능을 보여준다.
반면 연속된 데이터 타입(배열)은 업데이트할 위치를 찾기 위해 메모리 시작점부터 N 번의 반복문을 돌아야 한다. 그래서 Append, Remove 모두 O(N)의 성능을 보여준다.
데이터가 변경될 때 높은 성능을 보여주는 링크드 리스트가 왜 기본이 될 수 없을까?
조회가 문제다
데이터를 변경하는 데 있어서 링크드 리스트는 높은 성능을 보여주고 있다. 근데 왜 대부분의 프로그램에서 연속된 데이터 타입을 사용할까?
문제는 조회다. 링크드 리스트는 N 번째 데이터를 가져올때 N 번의 반복문을 실행해야 한다. 원하는 데이터 위치에 메모리 주소를 찾아야 하기 때문이다.
반면 배열은 데이터가 같은 메모리 영역 나열되어 있기 때문에 인덱스 * 데이터 타입 크기 + 시작 위치(C에서 ptr + n의 포인터 연산과 같다)로 연산을 통해 찾을 수 있다.
결론은 링크드 리스트는 O(N), 배열은 O(1)의 성능을 보여준다.
더 나아가 캐싱이 문제다
CPU는 업무를 수행하기 위해 메모리에서 필요한 리소스를 캐싱해둔다. 그리고 캐시 안에 들어있는 리소스를 레지스터로 가져와 업무를 수행한다.
근데 링크드 리스트는 서로 다른 주소의 데이터를 가지고 있다. 이렇게 되면 링크드 리스트는 루프 안에서 매번 다음 메모리 주소를 찾아야 하는데, 메모리와 상호작용하는 횟수가 많아지는 것을 뜻한다. 횟수가 많아지면 성능에 영향을 끼칠 것이다.
반면 배열은 연결된 데이터 구조로 되어있다. 특정 영역에 존재하는 데이터의 묶음을 한 번에 캐싱할 수 있다.
그러면 메모리에 접근하는 빈도수가 줄어들게 되고, 링크드 리스트보다 높은 성능을 낼 수 있다.
결론
대부분 프로그램 내부의 배열은 루프 안에서 조회되며 사용될 확률이 높다. 그렇기 때문에 대부분의 언어가 일반적으로 연속된 데이터 구조를 사용한다.
하지만 때로는 데이터의 조회보다 데이터의 수정이 주 업무가 되는 경우가 있을 것이다. 이럴 땐 적재적소에 맞게 링크드 리스트를 써보자.