크롬 드라이버 인스턴스를 생성했으니 페이지 로그인 및 파일 다운로드를 구현하자.
들어가기에 앞서
- 예제 코드는 pycrawler-exam을 통해 다운로드 받을 수 있다.
- [Python] 크롤링으로 업무 자동화 - (2)크롬 드라이버 인스턴스 생성를 안읽었다면 먼저 읽기를 권한다.
- 예제는 크롬 버전 78.0.3904.108, 웹 드라이버 버전 78.0.3904.70으로 만들어졌다.
페이지 분석
로그인하기 전 웹 페이지를 분석해야 한다. 아이디와 비밀번호 값 입력, 버튼 클릭 등 이벤트를 수행하기 위해선 해당 엘리먼트를 찾아야 되기 때문이다.
이전 포스팅에서 접속했던 깃허브 로그인 페이지로 접속한다. 그리고 크롬 개발자 도구를 열어준다. 보통 단축키는 F12키를 입력하면 되고, 안된다면 아래 이미지처럼 더 보기 아이콘 -> 도구 더 보기 -> 개발자 도구 메뉴를 클릭한다.
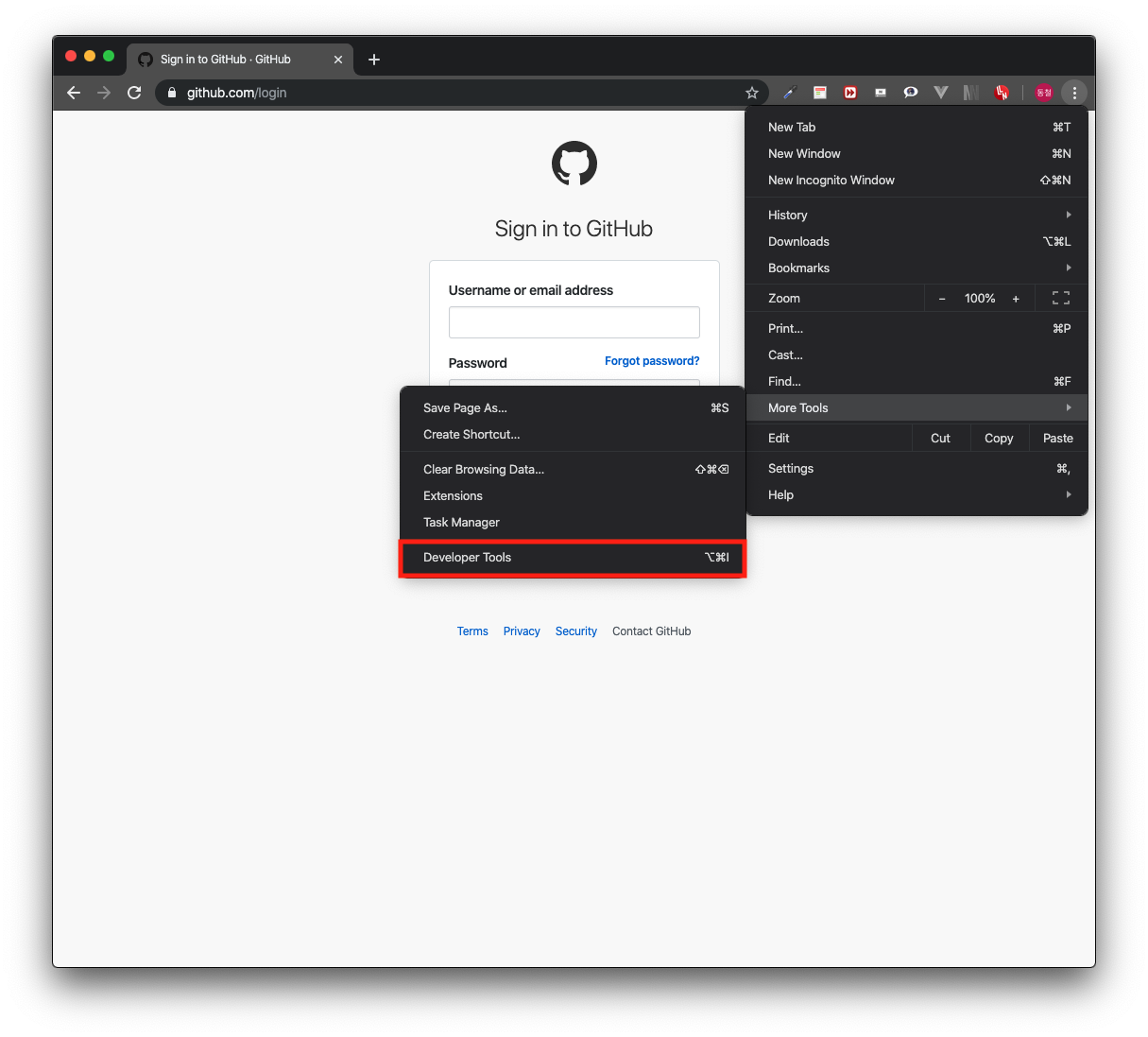 <크롬 개발자 도구 열기>
<크롬 개발자 도구 열기>
개발자 도구가 열리면 하단 또는 우측에 개발자 도구가 열린다. 개발자 도구 내부 Elements 탭을 활성화하고 개발자 도구 좌측 상단에 아이콘을 아래 이미지와 같이 클릭한다.
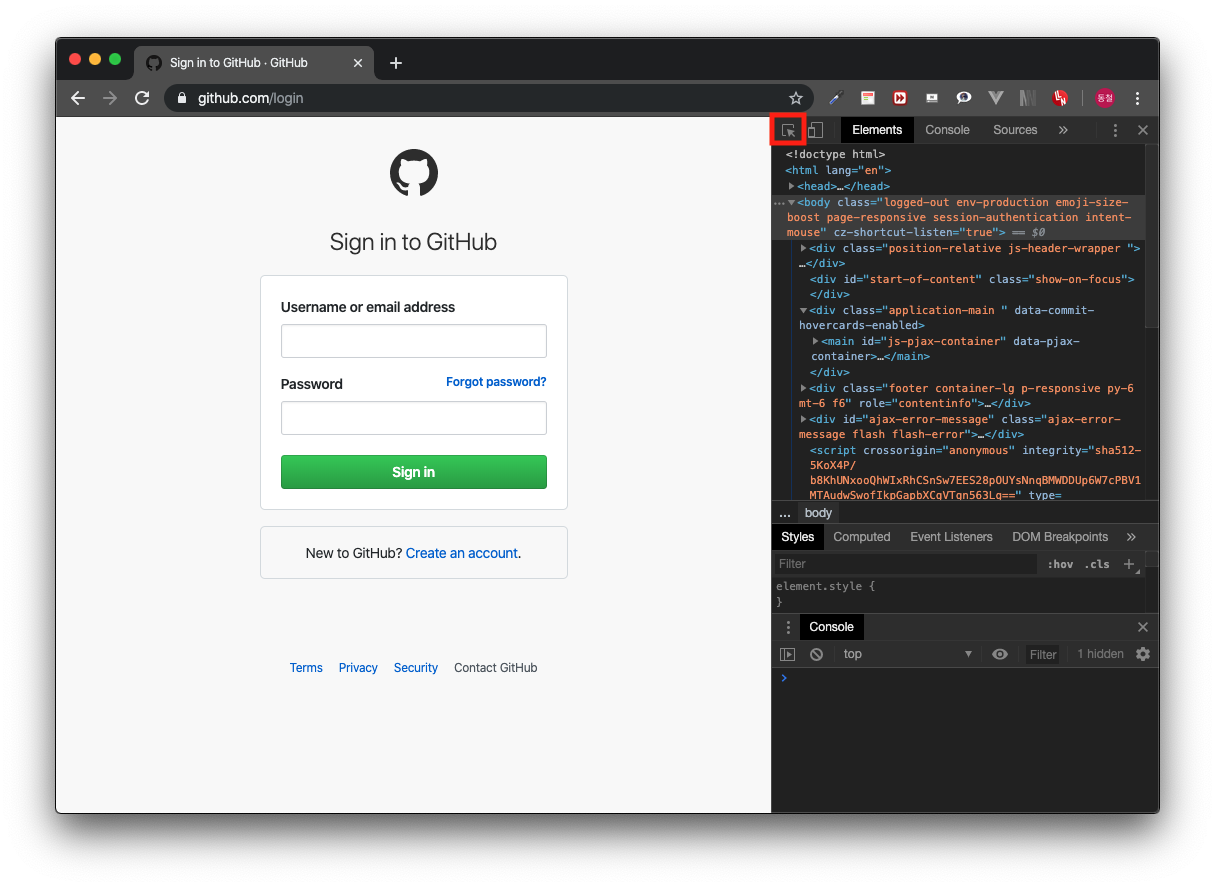 <크롬 개발자 도구>
<크롬 개발자 도구>
클릭하고 아이디 입력창을 클릭해본다. 그러면 아래 이미지처럼 아이디 <input> 태그의 정보를 볼 수 있다.
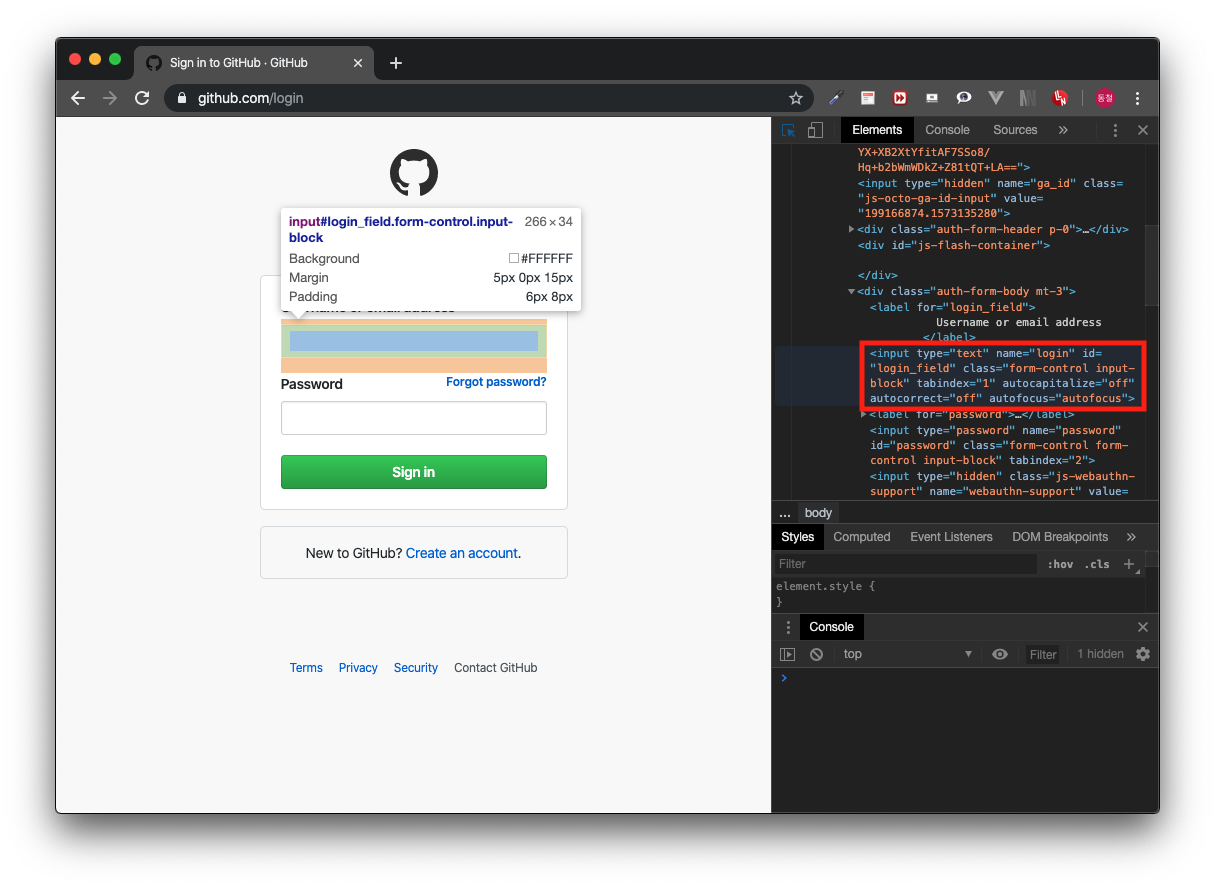 <아이디 엘리먼트 정보 확인>
<아이디 엘리먼트 정보 확인>
이렇게 개발자 도구를 사용하여 기본적인 브라우저 엘리먼트 정보를 확인해볼 수 있다. 크롤링이 아니어도 보안, 웹 개발, 업무 자동화 등 많은 분야에서 웹 분석은 활용되니 잘 알아두면 좋다.
로그인
개발자 도구를 사용하여 찾은 아이디와 비밀번호 <input> 태그에 로그인 정보를 입력해야 한다. 정보를 입력하려면 해당 엘리먼트를 크롤러에서 찾아야 한다. webdriver는 엘리먼트를 찾을 수 있도록 여러 함수를 제공하고 있다. xpath, id, class, name 등 방법은 많다.
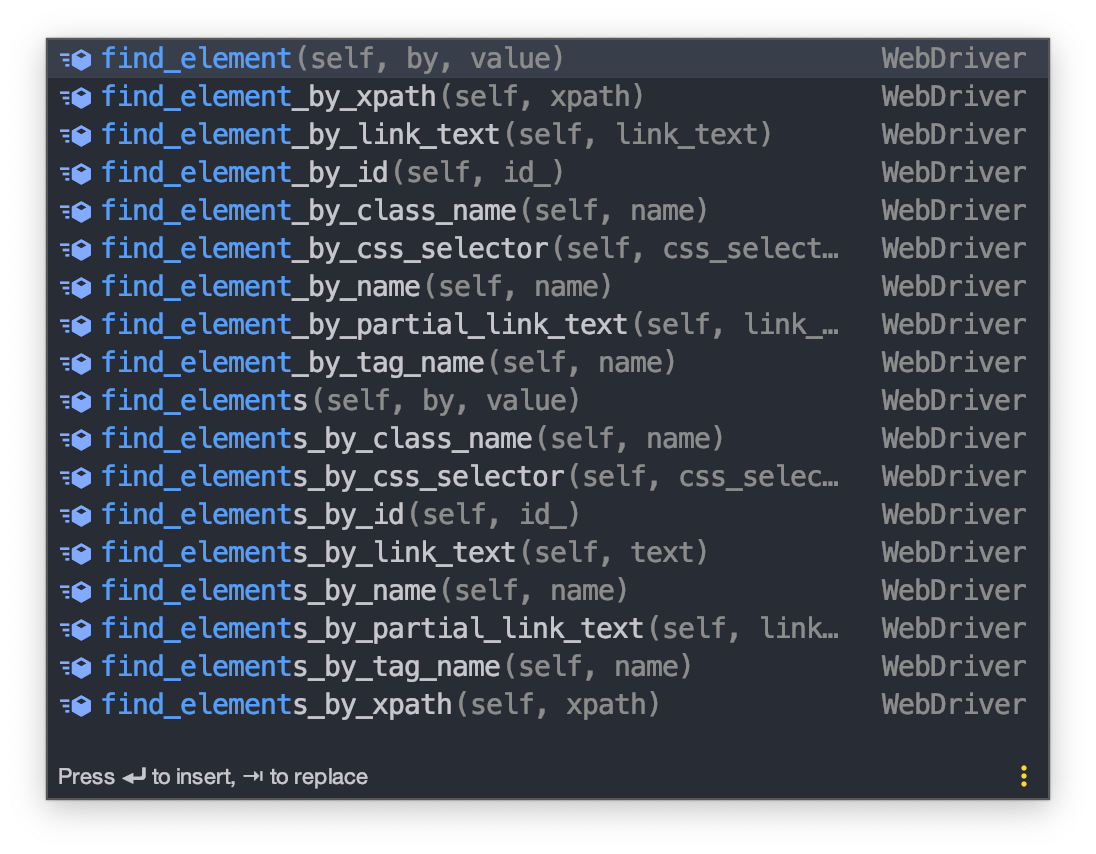 <엘리먼트를 찾는 함수들>
<엘리먼트를 찾는 함수들>
아이디와 비밀번호 입력 태그 정보를 보면 아이디는 id="login_field", 비밀번호는 id="password"를 포함하고 있다. 이 아이디 속성값으로 찾아보자. find_element_by_id() 함수를 사용하여 찾는다.
이전에 작성하던 main.py에 이어 작성한다.
1 | |
그리고 아이디와 비밀번호 값을 입력한다. 입력은 엘리먼트의 send_keys 함수로 전달한다. send_keys 함수는 양식을 채우거나 간단한 키 이벤트를 발생시키는데 사용하는 함수이다.
1 | |
로그인 정보를 입력했다면 로그인 요청을 위해 엔터키 이벤트를 발생시켜야 한다.
키 이벤트를 발생시키려면 from selenium.webdriver.common.keys import Keys를 추가해주자. Keys 클래스 안에는 다양한 키 입력값이 유니코드로 선언되어 있다.
엔터키 Keys.RETURN과 로그인 프로세스가 완료되는 걸 기다리기 위해 5초 정도 time.sleep()한다.
1 | |
코드를 추가하고 실행하면 깃허브 로그인이 되는 걸 확인할 수 있다.
파일 다운로드
로그인을 끝냈으니 엑셀 파일을 다운로드해야 한다. 엑셀 파일은 필자가 만들어 놓은 더미 데이터 레파지토리에서 다운로드할 것이다. 먼저 로그인 후 페이지 이동하는 코드를 추가한다.
1 | |
그리고 로그인 때와 마찬가지로 페이지를 분석한다.
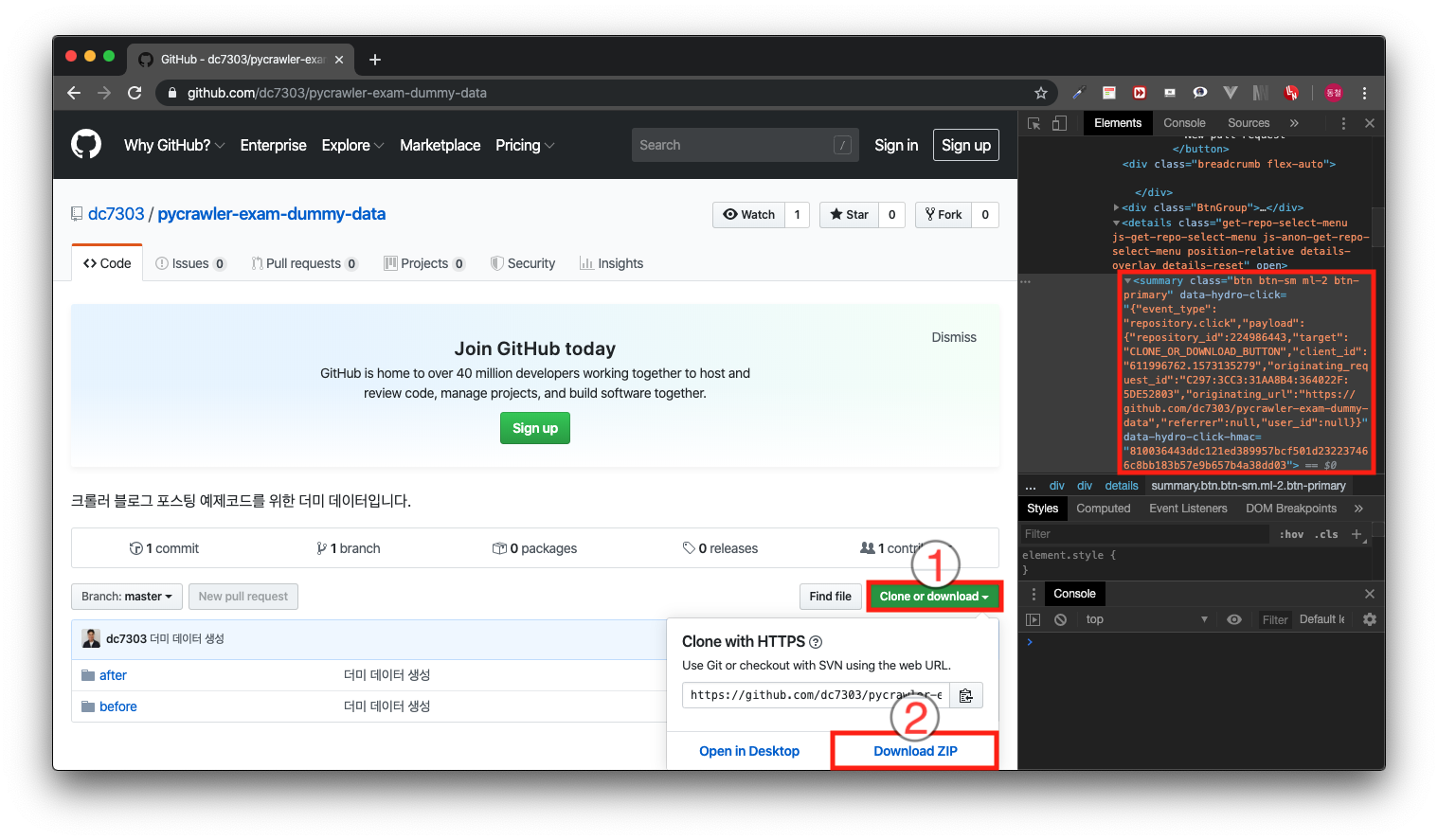 <파일 다운로드>
<파일 다운로드>
이미지처럼 파일 다운로드를 하려면 첫 번째로 Clone or download 버튼을 클릭한다. 그리고 두 번째로 활성화된 하단 토글 내부에 Download ZIP을 클릭하면 다운로드된다.
먼저 이 엘리먼트들에 접근하기 위해 Clone or download 버튼을 개발자 도구로 찾아보면 정보는 위 이미지 빨간 박스와 같다.
이번 엘리먼트는 아까보다 복잡하다. 이럴 때 XPath를 사용하여 찾으면 쉽게 해결할 수 있다. XPath는 XML 문서의 특정 위치를 찾을 때 사용하는 언어다. 개발자 도구는 특정 엘리먼트의 XPath를 쉽게 작성하도록 도와준다.
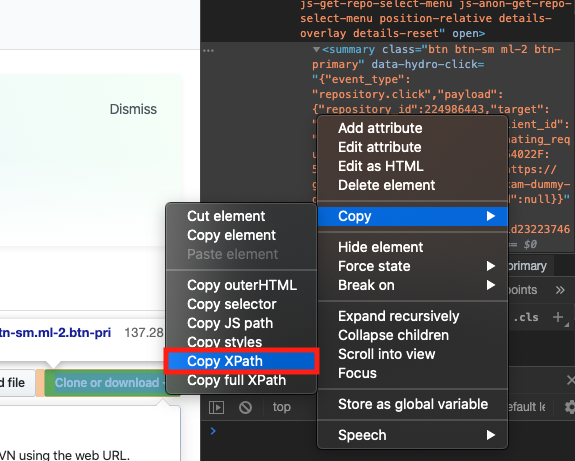 <XPath 복사>
<XPath 복사>
이미지처럼 원하는 엘리먼트 위에서 마우스 우클릭을 하면 메뉴가 나온다. 여기서 Copy -> Copy XPath를 선택한다.
복사한 값을 find_element_by_xpath() 함수의 파라미터 값으로 사용하여 엘리먼트를 찾는다.
1 | |
이렇게 찾은 Clone or download 버튼을 클릭해야 한다. 클릭 이벤트는 엘리먼트의 click() 함수로 발생시킬 수 있다.
1 | |
그리고 활성화가 되었을 때 Download ZIP 버튼을 클릭해야 다운로드가 된다. 이전과 동일한 방식으로 XPath를 활용하여 Download ZIP 엘리먼트를 찾고, Download ZIP을 클릭하는 코드를 추가한다. 다운로드 완료까지 시간이 걸리니 5초 정도 time.sleep해준다.
1 | |
이렇게 코드를 추가해주면 main.py 파일 코드는 아래와 같다.
1 | |
그리고 이 코드를 실행해본다.
1 | |
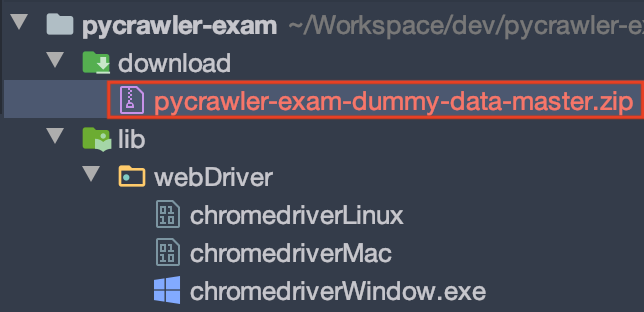 <파일 다운로드 완료>
<파일 다운로드 완료>
코드가 실행되고 브라우저에서 파일 다운로드가 안료 된다. 그리고 프로젝트 내부 download 디렉토리에 파일이 다운로드되었다면 성공이다.
다음 포스팅에서는 다운로드된 zip 파일을 풀고, 데이터를 비교를 다루겠다.